A Flexible View Control for XPages Part 9 – Using Scroller for Large Views
Posted: May 4, 2020 Filed under: Bootstrap, DataTables, Domino, JavaScript, XPages | Tags: Bootstrap, CSS, DataTables, Domino, JavaScript, XPages 2 CommentsUp to this point, the examples I’ve created to demonstrate the capabilities of the FVC have used fairly small sets of data. In a real-world production scenario there is going to be a need to display datasets of various sizes, including thousands of records. So how does the FVC scale for larger sets of data?
Understanding DataTables
Comprehending what is going on behind the scenes of DataTables is vital to developing a strategy to handle large sets of data efficiently. Similar to XPages, DataTables has a “lifecycle” where a series of events occur in the initialization of the table. Previously, I created a bunch of “pure” DataTables demos, one of which highlights the various phases (callbacks) of the lifecycle (turn on your developer console):
http://demos.xpage.me/xpages/mwlug/datatables.nsf/demoRestLifecycle.xsp

The image above shows browser consoles statements to demonstrate what the lifecycle looks like for a DataTable with 25 records. Take a close look and you’ll see that drawCallback executes multiple times. This means DataTables has drawn the table twice as part of the initialization. A good comparison to this in the XPages lifecycle is the renderResponse phase.
Now, let’s focus on the rowCallback and createdRow callbacks. In this table with 25 rows each of these is called every time DataTables processes a row of data. Normally, you are likely to only use one or the other – both are included here for demonstration purposes. Regardless of which callback you use, the code that resides there will be executed for each row. If your DataTable is replicating the functionality of a Notes View, then you’re likely to have click and double-click events at a minimum.
Now imagine you have a view with a large amount of data – thousands of records, for example. Your rowCallback is now executing THOUSANDS of times, resulting in slower rendering of your DataTable and negatively impacting the user experience. YIKES!
Large Datasets – Notes Views vs. Web Views
Anyone that has used Lotus Notes and Domino for years has been spoiled by having views with thousands (or millions) of records, nicely indexed, and extremely performant as you click on columns to re-sort or search the view based on a key. This is one thing that Notes does really, really well, but sending thousands to millions of rows to a view in a web application can seem like a fool’s errand.
While I certainly continue maintaining large Notes views on the back-end, I use categories, keys, and server-side searching to make it easy for users to target the information they need so only a small subset of information is sent to the client-side web view.
I feel like my magic number is about 5000 records or less. Any more than that and users are waiting too long. Obviously, there are going to be use cases where that is not possible and there are other factors to consider, such as server processing power and bandwidth between the client and server.
Pagers
Paging is one way to deal with large amounts of data and can be turned on with a simple paging: true as part of the initialization options within DataTables. But let’s say you have 4000 records and 50 records show up on each page. This results in 80 pages. Do you want to page through 80 pages of data? Do you want your users to page through 80 pages of data? NO!
Enter Scroller
I’ve said this before in previous posts and presentations but it bears repeating again – the more I use DataTables and the more I have challenging business requirements that at first glance seems like I might have to hack a solution together, ultimately DataTables has a fairly simple way to achieve the desired result. Displaying large amounts of data in a performant way is no different.
DataTables has a plugin called Scroller that does a great job of managing large amounts of data. It does so by only “drawing” the rows that are visible within the scroll body of the table plus extra rows so when the user starts scrolling the table is able to respond quickly. As the user scrolls, the scroller plugin draws more rows. All of the features of DataTables still work as you expect them to – filtering, sorting, etc. Technically, DataTables is using paging functionality behind the scenes to manage the data,
Enabling Scroller in the FVC
The Flexible View Control has the ability to utilize Scroller. Do the following to turn it on:
- Make sure you are loading the Scroller plugin resources. I’m loading the plugin via a CDN in my theme:
<resources>
<styleSheet
href="https://cdn.datatables.net/scroller/2.0.0/css/scroller.dataTables.min.css">
</styleSheet>
</resources>
<resource>
<content-type>application/x-javascript</content-type>
<href>https://cdn.datatables.net/scroller/2.0.0/js/dataTables.scroller.min.js</href>
</resource>
2. You must have showFixedHeader: true on your FVC. Scroller will not work properly without fixed headers being turned on.
3. Set scroller: true in the FVC custom properties.

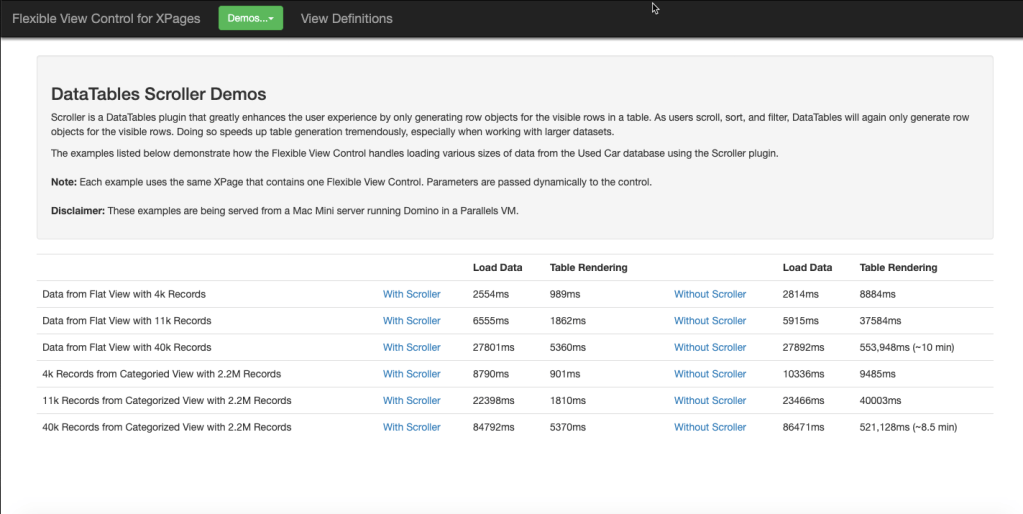
Demos
This page contains multiple demos that illustrate the dramatic effect scroller has on loading large amounts of data.
Focusing on the first line of the page above, these two sets of console statements highlight the significant difference in loading time between two tables that have the same ~5000 records, one without scroller, one with scroller.
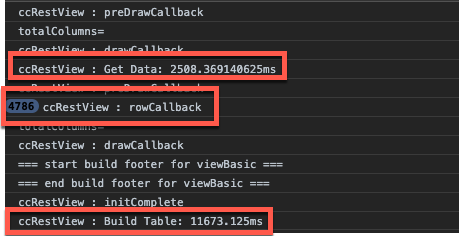

- The first thing we notice is the data is retrieved from the server in the same amount of time in both scenarios.
- In the first console image where scroller is not enabled, every row is being processed by DataTables at initialization, which drastically slows down the table build vs. the second console image, where scroller is enabled.
- Finally, we see a dramatic difference in the build times between the two tables. 11 seconds is a lifetime compared to 1 second and as tables get bigger the 10-second difference will grow in magnitude.
Some Minor Side-Effects
Using scroller does come with a couple of side-effects, but they are fairly minor and shouldn’t have much of an impact.
Since the scroller plugin relies on precise calculations to build the table rows, it forces each row to be the same height. This is really only a problem if you have one column that has one or more records that have extraordinarily long data. Scroller will stretch that column out so all of the data can fit within that row height.
Luckily, the FVC View Definition makes it easy to overcome this. All you need to do is explicitly define a max width for your column and check the “Hide Overflow” box:
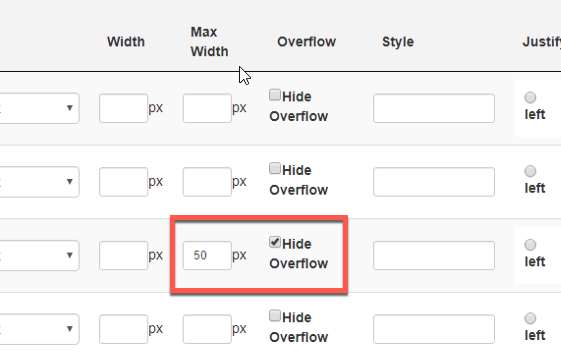
The result is your column tries to honor the width you’ve assigned and any text that exceeds that width is truncated with an ellipsis:

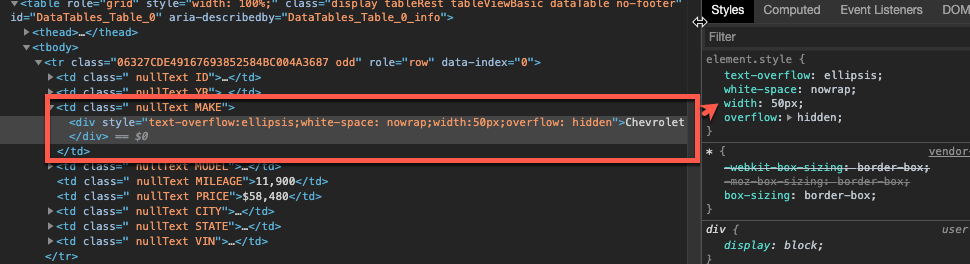
The other noticeable side-effect is simply cosmetic and can easily be overridden with CSS. When a table does not have enough data to fill the table body, scroller fills the white space with a background image:
If your users don’t like it, you can use the following CSS to override the background to be whatever you want:
div.dts div.dataTables_scrollBody {
background:#fff;
}
Conclusion
The numbers above are pretty clear – using scroller will greatly improve the performance of the Flexible View Control when your table has a large amount of data and a difference can be seen with as few as 2-300 records. Every view in my application now has scroller enabled.
