This one trick helps you analyze your Notes data!
Posted: July 17, 2020 Filed under: Uncategorized | Tags: data analysis, Notes Leave a commentCheesy click-bait headline aside, I did recently have a need to analyze millions of records in a database and get a feel for what type of non-alphanumeric characters existed in one field in particular.
What I came up with was an incredibly simple view that gives me a count of how often every combination of English non-alphanumeric characters appears in this one field.
column1: Categorized with the following formula:
str := "abcdefghijklmnopqrstuvwxyz1234567890 ";
@Explode(@Trim(@LowerCase(field_name));@NewLine+str)
column2: Totals column.
The results are… interesting, to say the least.
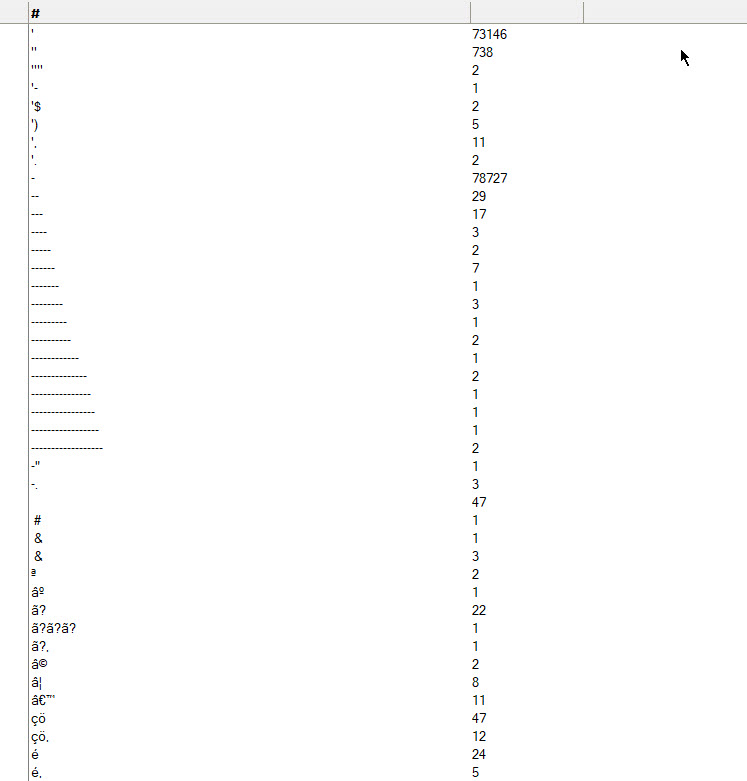




The “Not Categorized” category contains all the documents that do NOT have non-alphanumeric characters in field_name.
This type of analysis can be handy if you don’t have control over the input – for example, if your database contains a large amount of data from external sources or if users do a lot of copy and paste from external emails, Word docs, PDFs, and other files.
